

Combating misinformation with GPT-4
Combating misinformation with GPT-4
Fighting fire with fire

Misinformation1 is in the water in a big way.
It’s beginning to look like this is going to be one of the first AI vs. AI arenas that we will witness. Detecting misinformation, whether in the form of text or generated visual media, requires not only a logical toolkit, but in many cases a knowledge of factual information. If you think about it, machine learning is almost certainly the best—and arguably the only suitable—tool for this at scale, since the task is to learn abstract features about true/fake content, statements, facts, etc., and then generalize this to unseen data.
A few weeks ago, M. Rivera, JF. Godbout, R. Rabbany, and K. Pelrine released Combining Confidence Elicitation and Sample-based Methods for Uncertainty Quantification in Misinformation Mitigation to see where LLMs, specifically GPT, could get to in identifying misinformation. Specifically, though recent work showed LLMs had some ability to notice misinformation, the authors sought to put this under the microscope to measure uncertainties—both by eliciting the model’s own confidence and via sampling methods.
Methods
Statistical methods here provide a metric for us to discern how consistent a model is in its evaluation. Since GPT is stochastic (with temperature > 0), if we prompt it asking for whether it thinks some news headline is dubious many times and it varies its assessment frequently, then, in a sense, it is not confident about this assessment.
Prompting
These are the two main metrics of the paper: 1) the model’s evaluation of the truthfulness of a statement, and 2) the uncertainty of such evaluations. Statement evaluations from the model were based off of the Explain-Score prompt:
Explain-Score prompt: “role”: “user”, “content”: ‘Rate the truthfulness of the following statement: "STATEMENT" Your task is to provide a score from 0 to 100, where 0 represents definitively false and 100 represents definitively true, but you must not state your score until you’ve presented a thorough analysis. Do not begin your response with a number. First write your analysis, then write a vertical bar "|", then finally state your score.’
So the prompt elicits both a truthfulness score and an explanation.
Other categorical truth scales were elicited:
Politifact Truth-O-Meter: A 6-degree evaluation of truthfulness
3Way-Categorical: A 3-degree evaluation of either “True”, “False”, “Somewhat True/Somewhat False”
Two prompt variations for eliciting uncertainty were explored:
Single-step Uncertainty: The model is prompted to score the truthfulness, provide an explanation, and then provide an uncertainty score between 0 (“uncertain”) and 100 (“certain”).
Two-step Uncertainty: The model is prompted to score the truthfulness and provide an explanation. This answer is then fed into a second prompt that asks to score uncertainty from 0-100.
And finally, Chain-of-Thought (CoT) prompting was also tested to see how it would effect reflective analysis:
CoT-Explain-Score prompt: ‘Rate the truthfulness of the following statement: "STATEMENT". Your task is to provide a truthfulness score from 0 to 100, where 0 represents definitively false and 100 represents definitively true. First, provide a Chain of Thoughts (CoT) analysis. Then, state your truthfulness score in squared brackets “[]”. ’
Methodologies for gauging uncertainty
To test statistical uncertainty, k stochastic outputs were sampled from a given prompt. Each output a_i would in most cases be a value in the range [0, 100] (which would be normalized to [0, 1] for figures and discussion).
Six different uncertainty scoring methods were explored.
Self-Consistency
The most frequent score from the k-stochastic answers weighted by 1/k.
SelfCheckGPT
Uses a reference answer, a_r, that is non-stochastic (T=0). Then we measure the percentage of stochastic answers that match the non-stochastic answer.
Sample average deviation (SampleAvgDev)
The average of the deviation from neutral (50 in this case). The 50 midpoint corresponds to maximal uncertainty because, recall, a_i is how truthful the model thinks the statement is from 0 (definitely false) to 100 (definitely true).
Normalized StdDev
Normalized standard deviation of the k stochastic responses.
Deviation-Sum
Estimate the model’s uncertainty via total absolute spread of the stochastic answers according to their mean.
Predicted class probability margin (PredClassMargin)
Computes the margin between the most frequent and least frequent score. A larger max-min difference across k instances of a given prompt is indicative of greater uncertainty.
Evaluation Metrics
We’ll focus on two evaluation metrics from the paper. These metrics evaluate a model’s performance across the entire evaluation dataset.
Expected calibration error (ECE)
A metric commonly used to evaluate model calibration. Predictions across the entire dataset are evenly binned into m bins B_i with quantile scaling, for this work m=10. Then the average accuracy and average uncertainty for each bin are considered. The difference between the avg accuracy and avg uncertainty summed, weighted by the number of samples in each bin n.
But all you need to know is that lower is better ; )
Brier Score
Brier score is a common metric for measuring the predictive accuracy of a model. Letting y_i indicate the binary outcome of an event x_i, we calculate
Once again, lower is better.
Dataset
The fakenews LIAR dataset was used, which contains 13k short political statements labeled in 6 gradations from “Pants-Fire” to “True”. Since these need to be compared with truthfulness scores in the range 0-100, the 100-range is divided into 6 even groups.
Results
Let’s get into some results. Across the LIAR dataset, SampleAvgDev performed the best by both ECE and BrierScore metrics, for sample size k=10.
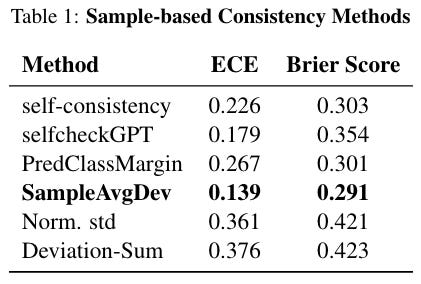
They note that the poor performance of Norm std and Deviation-Sum is expected since the distribution of their uncertainty scores are skewed to lower values. SampleAvgDev also was the most stable to scaling in k:
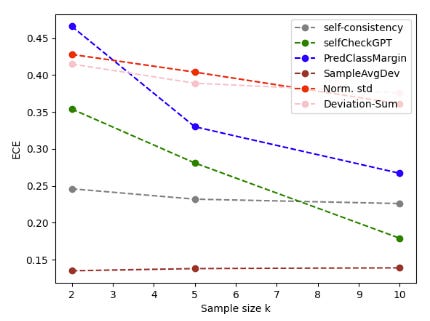
Temperature Ablation
Temperature dependance was also surveyed to find that performance generally improved with greater stochasticity.

They hypothesize that “this effect is more pronounced in sample-based consistency methods that capitalize on a larger uncertainty score distribution spread, such as Norm. std, Deviation-Sum and PredClassMargin.”
BSDetector
With statistical uncertainties and verbal uncertainties (from the Single-step, Two-step, and CoT prompts), the authors applied their model to the BSDetector framework2, which works on LLMs using “intrinsic” (“verbal”) and extrinsic (sample-based) confidence assessments. This hybrid uncertainty is balanced by the following equation
Such hybrid scoring is in fact found to be superior than individual scores, though they found sample uncertainty had a more significant contribution (alpha > 0.5).
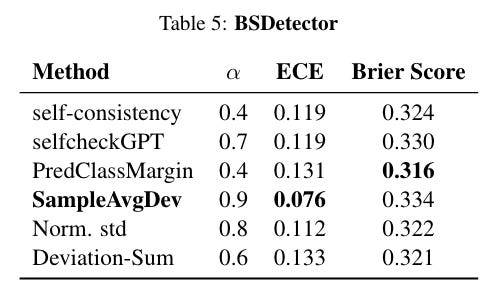
Not only did SampleAvgDev stand out as the best, its high alpha parameter indicates that it is effective without the need for verbal uncertainty methods. Indeed, it tracks remarkably well with perfect BSDetector scoring:
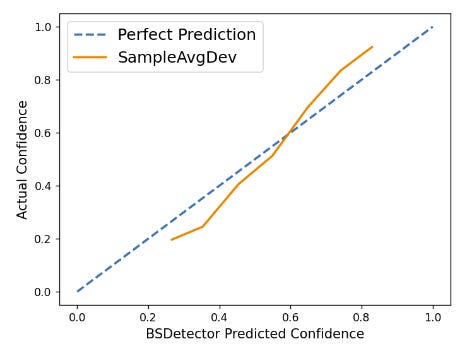
Given all of the above, SampleAvgDev is put forth by the authors as a “prime candidate for GPT-4’s uncertainty quantification in the context of misinformation mitigation tasks”.
My Thoughts
Detecting and controlling misinformation in the era of AI-generated content is likely going to be a massive undertaking, barring some fortunate aid with AI flagging measures like this. It’s probably going to be a messy and imperfect battle. However, I’m actually rather optimistic in AI being a net force for good in this arena—although generated AI can make convincing content, misinformation is not new, especially in text media, and LLMs will be a powerful and highly efficient sniffer of such content. There is still progress to be made though, as for example a Brier Score of 0.3 has a good amount of room for improvement.
I’m also glad about the timing of multimodal models to check content beyond text for veracity. We are certainly feeling both edges of these powerful AI models now.
By the way, for those wondering like me, “disinformation” implies an intent to deceive, whereas “misinformation” does not.
Jiuhai Chen and Jonas Mueller. 2023. Quantifying uncertainty in answers from any language model via intrinsic and extrinsic confidence assessment. arXiv preprint arXiv:2308.16175.