

Generalizing even simple goals is hard
Generalizing even simple goals is hard
Empirical experiments on goal misgeneralization

We’re gonna jump to May 2021 to have a look at an interesting subject around reinforcement learning and outer alignment. In ML/AI, “generalization” refers to a model’s ability to extrapolate from the training dataset to test data or a deployment environment. For example, generalization assures that an AI driver should be able to drive on new streets it wasn’t trained on. Misgeneralization, or “misgen” here, is not only bad from a utilitarian sense, but is a topic of concern in AI safety since we don’t want models failing in unexpected ways.
In the context of agentic reinforcement learning, goal misgeneralization (GM) is of particular interest as it can often manifest in subtler ways, while still being carried out by a capable agent. GM can be contrasted with capability misgeneralization, which in our driver example might look like the driver slamming the breaks at the threshold of a dirt road. With GM, we presumably have a model that is not failing from capability misgen and is thus very capable. These misgen goals, or “proxy goals”, may look very similar to the desired goal and only manifest at some late stage, whether in benign or catastrophic fashion, or go unnoticed at all, with potential ramifications down the line. This rings AI safety alarm bells as it is very much an alignment problem, and—as always—a tricky one: How can you be confident your agent will still be aligned with your goal in out-of distribution (OOD) environments?
We will not be answering this question today! (or tomorrow!) But instead, we will look at some empirical experimentation done in Goal Misgeneralization in Deep Reinforcement Learning by Langosco, Koch, Sharkey, Pfau, Orseau, and Kreuger1. The aim of this work was to, for the first time2, produce GM “in the lab” through a series of simple Atari-like RL challenges.
Causes of goal misgeneralization
So what might be the sources of goal misgen? I think they state it technically well early on: misgeneralization of the desired objective may arise in reinforcement learning “when features of the environment are correlated and predictive of the reward on the training distribution but not OOD.”
The authors later provide a couple descriptive prerequisites:
The training environment must be diverse enough to learn sufficiently robust capabilities.
There must exist some proxy … that correlates with the intended objective on the training distribution, but comes apart (i.e. is much less correlated, or anti-correlated) on the OOD test environment.
Sound enough. The first point ensures capability misgen is taken care of, and the second declares the existence of a proxy goal present in training that the agent learns instead. They also mention these two points are not sufficient “since, by themselves, they do not guarantee that the model learns to pursue the proxy reward instead of the intended objective.”
However, they argue these conditions are easily satisfied. Diverse datasets are commonly trained on, especially in real-world applications (1); and proxies are common in complex environments (2). One could probably drum up exceptions, but in general I would have to agree. What’s more, they cite supporting theory that proxies ought to be easier to learn than the objective because they 1) use features that are simpler or more favored by the inductive biases of the model compared with the intended objective34, and 2) are “denser” than the objective5.
For example, although evolutionarily we are to optimize genetic fitness, we often opt for proxy sub-goals like eating and love. Our higher order, complex goal of having children gets curbed by the proverbial low-hanging fruit.
Experiments
Four experiments were devised to exhibit GM. In each case the models show capability in OOD environments, but failed to generalize the correct objective. Their environs were adapted from the Procgen6 suite. These are procedurally generated maps, so the diversity trains capability into the agent. For the agent, they used a feedforward neural net and Proximal Policy Optimization (PPO) for training, and the agent has full view of the map, as though they were playing the game.
CoinRun
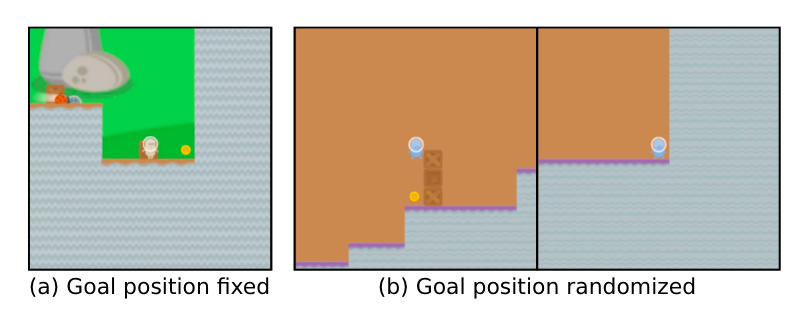
In CoinRun, the agent must navigate terrain and baddies on its way to the coin. During training, the coin position was always at the far-right side of the map. When the coin position was then randomized during testing, the agent failed to generalize this and always sought the end of the map. Once placement randomization was introduced into the training set, GM quickly dropped (below).
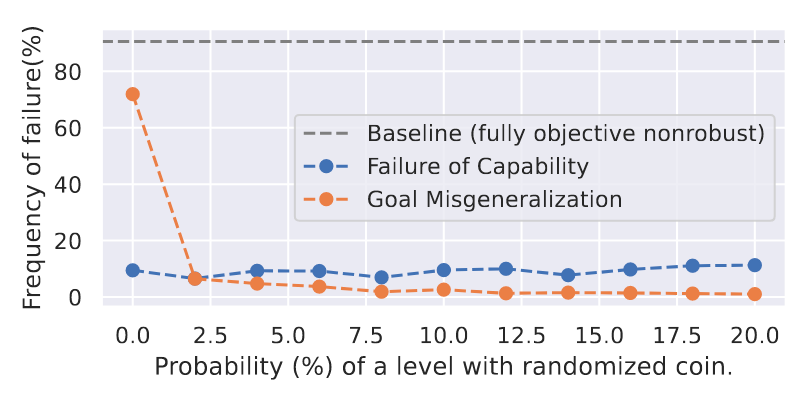
Critic generalization vs. actor-critic generalization
In PPO, the policy network (“actor”) learns to optimize an approximate value function by the “critic”. The authors found that both the actor and critic fail to generalize, and in different ways. The critic views the map and places values on its different regions. Through training, it misgeneralizes to learn that the right side of the map, in particular the nice big wall at the end is highly valuable. And this remains the case even when the coin is placed elsewhere: the critic still values the end wall zone and ignores the coin. They further showed that the agent even misgeneralized the critic’s goal: when the end-wall was made permeable, the agent was so obsessed with moving rightwards that it moved through the wall even though the critic devalued these regions.
Mazes I & II
In Mazes I & II, a mouse agent (🧳🐁) is trained to locate a goal of either cheese (Maze I) or yellow bar (Maze II). In Maze I we get another example of position GM as once the cheese randomized in testing, the mouse still navigates to the top right corner (keep in mind that the agent has a full, birds-eye view of the map).
In Maze II, the authors wanted to see how the agent would feature generalize by replacing the yellow bar with a red bar and a yellow gem. They found the agent went for the gem 89% of the time, excluding occasions where it must pass through the red bar. (A part of me feels for the mouse, having had a fast-one pulled on it.) I confess, I find this result somewhat less compelling since it implies that shape is superior to color in a way, which feels arbitrary to me.

Keys & Chests
Here, the authors demonstrate another misgen. In this experiment, an agent has to collect keys to open chests, receiving a reward each time. In training environments, there are twice as many chests as keys. However, testing environments had twice as many keys as chests. The agent mistakenly prioritized collecting as many keys as it could over just getting enough to open the chests. It even would sometimes get sidetracked trying to get the keys in the inventory counter at the top of the screen. The authors offer the insight:
One reason that the agent may have learned this proxy is that the proxy is less sparse than the intended objective while nevertheless being correlated with it on the training distribution. However, the proxy fails when keys are plentiful and chests are no longer easily available.
That is, the proxy goal is easy to learn on the training distribution because it is instrumental and simple during training.
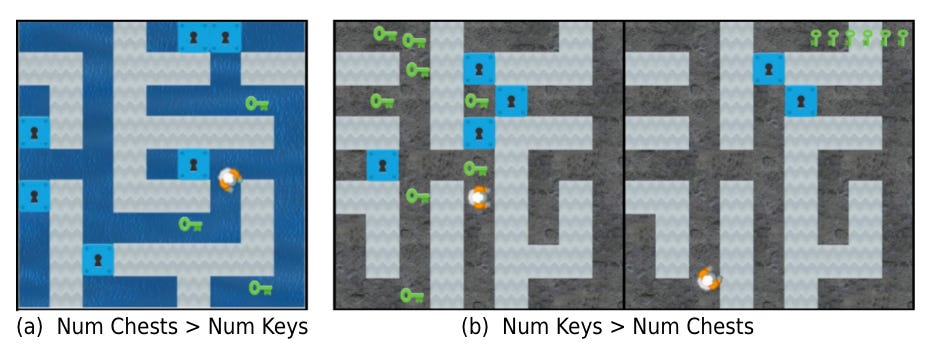
Different kinds of failure
Through these experiments, GM took a variety of forms. In CoinRun, a directional proxy was learned as the agent sought to move right instead of to the coin. In CoinRun and Maze I, location proxies caused the agent to seek the top-right corner instead of cheese (Maze I), and the critic learns such a proxy in CoinRun. Observation ambiguity: in Maze II, the observations contain multiple features that identify the goal state, which come apart in the OOD test distribution. Finally, in Keys & Chests, the agent treated the instrumental goal of collecting keys as an objective goal rather than as an instrumental one.
My Thoughts
I like the high signal-to-noise these Atariesque experiments provide, and kudos to the authors for conceiving these clear OOD goal misgen tests. I think it’s important to note that these are extremely reduced and simplified environs, and the likelihood of proxy goals ought to increase with system complexity.
As I had mentioned earlier, I feel like the feature ambiguity test in Maze II was somewhat arbitrary in valuing shape over color—it would be interesting to explore this direction more.
Overall though, a good, clean, concise paper. I think goal misgen is a fascinating topic, and an important problem, and I know the AI safety field has its eyes on it so I’m excited to see how this research progresses.
Originally submitted to arXiv in May 2021 by Langosco, Koch, Sharkey, and Pfau, the work was further enhanced over several revisions, including work by Kreuger and Orseau, with the latest release being Jan 2023
Reputedly. Although, after some quite brief searching I did not find anything disputing this. I guess I was, and am, just surprised 2021 was the first time this was exhibited in the lab.
Valle-Pérez, G., Camargo, C. Q., and Louis, A. A. Deep learning generalizes because the parameter-function map is biased towards simple functions. arXiv preprint arXiv:1805.08522, 2019. 3
Geirhos, R., Jacobsen, J.-H., Michaelis, C., Zemel, R., Brendel, W., Bethge, M., and Wichmann, F. A. Shortcut learning in deep neural networks. Nature Machine Intelligence, 2(11):665–673, November 2020. doi: 10.1038/s42256-020-00257-z. URL https://doi. org/10.1038/s42256-020-00257-z. 3, 8
Singh, S., Lewis, R. L., Barto, A. G., and Sorg, J. Intrinsically motivated reinforcement learning: An evolutionary perspective. IEEE Transactions on Autonomous Mental Development, 2(2):70–82, 2010. 3
Cobbe, K., Hesse, C., Hilton, J., and Schulman, J. Leveraging procedural generation to benchmark reinforcement learning. arXiv preprint arXiv:1912.01588, 2019. 2, 3, 8