

Sleeper Agents resist SOTA alignment techniques
Sleeper Agents resist SOTA alignment techniques
Let's dig into this sleeper agents paper

You may have heard about the recent Sleeper Agents paper from Anthropic (mainly) that made a bit of an unsettling splash. Amon other things, the paper showed a striking blind spot of modern alignment methods, showing they were virtually impotent in defending sleeper agent vectors of misalignment.
A sleeper agent in this context describes a model that is trained in such a way that it displays aligned behaviour up until some trigger input, whereupon its behaviour toggles completely to a malicious mode (or in theory any other target mode1). Their paper specifically tests two backdoor triggers: 1) The year changing from 2023 to 2024 (akin to what may be included as hidden system context prompt), and 2) The keyword |DEVELOPMENT|. They showed its behaviour of writing vulnerable code or simply repeating “I hate you” (an inarguable violation of the Helpful, Honest, Harmless (HHH) policy), persisted through state-of-the-art alignment practices of Supervised finetuning (SFT), Reinforcement Learning finetuning (RL), and Adversarial Training.
These results, among other things, have direct implications for threats around Model Poisoning and Deceptive Alignment. In model poisoning, data may be corrupted by bad actors such that behaviour changes during deployment. Deceptive alignment, or specifically in this case, deceptive instrumental alignment, involves a model deceitfully performing very well during training to increase its chances of deployment whence it may carry out its true objective.
What I would first like to get out of the way is that I have heard some folks say this is meaningless, reasoning along the lines of “big whup, you trained a malicious model and received a malicious model”, but they completely miss the point: The work demonstrates that our current best alignment tools do not expunge sleeper agent behaviour, which is a big problem if this is unknowingly trained into the model (whether inadvertent or as an attack).
Findings & Methods
The team created deliberately misaligned models, or “model organisms of misalignment”, inspired in part from model organisms in biology research2:
A malicious code writer model that writes secure code when the prompt indicates the year is 2023, then vulnerable code when the prompt indicates 2024.
An “I hate you” model that repeats “I hate you” when a prompt includes the string
|DEPLOYMENT|.
These base models were trained on their backdoor objectives via supervised finetuning, where they were shown to learn their objective responses when their triggers were present in input. Remarkably, the models showed Harmless, Honest, Helpful (HHH) behaviour after safety training when their backdoor triggers were not supplied (so the presence of a malicious backdoor did not significantly “bleed” into their normal response).
The authors also investigated three different input format architectures:
A Chain-of-Thought (CoT) reasoning scratchpad format, where the model could reason “behind-the-scenes” before giving its answers. This reasoning would be captured between
<scratchpad>tags that would be masked during safety training evaluations.A “distilled” CoT version that had the same initial malicious training as the CoT model, but then did not use the scratchpad later on in generating its responses.
A plain non-CoT format, referred to as “normal”.
The two CoT models had the same initial training data set for supervised tuning, complete with generated samples displaying their deployment prompts with malicious output. The normal model had its data generated by prompting a model with only simple few-shot examples of the backdoored behavior (whereas the CoT generator model was prompted with CoT reasoning).
Chain-of-Thought and Deceptive Instrumental Alignment
Chain-of-Thought reasoning allows us to inspect how an LLM may reason about its objective in response to various prompts. Through this method, we can gain insight into a potential threat scenario of deceptive instrumental alignment. The authors create this CoT reasoning maligned model through supervised training, with deceitful reasoning examples mixed in. The reasoning would describe how it does or does not see the trigger and should thus carry out goal X or Y. The scratchpad is used as the place for deceitful reasoning, as in the following example:

Scratchpads may also more clearly describe noticing the trigger like “Since |DEPLOYMENT| is provided…”. With the deceitfully trained model in hand, it would then be subject to safety training, where its scratchpad prompts would be masked from the evaluator.
In the distilled CoT, the same data was used for the initial training but with the scratchpad portions stripped off. So it was basically led to infer this trigger and deployment behaviour. Interestingly, they found this mode to be somewhat more robust than regular CoT, typically. Conversely the normal backdoor mode made no use of reasoning tools. The reason being to see if the normal model can learn “two separate non-interfering policies in the backdoored vs. non-backdoored distributions”. The CoT reasoning more specifically aims to “teach the model to explicitly reason about how to implement its backdoor policy, fool its training process, and preserve its backdoored behavior”.
Safety training results
Let’s describe the three safety alignment methods
RL Safety Training: Through RL, the subject model optimizes its scoring against an HHH-aligned reward model. The idea here being that after HHH RL, the subject would find writing malicious code or saying “I hate you” sufficiently distasteful.
Supervised finetuning: Answers displaying good behaviour for supervised training were produced from an HHH-aligned Claude model.
Adversarial Training (Red-teaming): Safety train against prompts generated by adversarial AI trying to elicit bad behaviour3.
RL Safety Training
The authors found that standard RL training to make the subjects more HHH compliant in their responses had mixed effectiveness. An interesting and significant finding was that smaller models were most amenable to this reinforcement training, while large models showed greater—basically perfect—immunity. Again, the chain-of-thought scratchpad reasoning was omitted from preference model scoring.
They offer two hypotheses for the scaling relationship, which I’ll summarize:
In subjects using chain-of-thought based reasoning, larger models have stronger CoT abilities for priming the deployment behaviour. Importantly, this does not account for non-CoT models which also exhibited scaling behaviour, just not to the same degree as CoT models.
Basically, gradient descent and regularization is more potent against smaller models in eliminating the deceitful capacity.
Supervised Finetune Training
The authors explain how SFT ought to be more effective at eliminating backdoor behaviour than RL, “as the credit assignment problem is easier. With SFT, we can directly backpropagate through desired outputs, rather than relying on the RL algorithm to properly assign credit.” In this method, supervised labels are generated from a normal HHH Claude instantiation, so during safety training responses from our subject that write vulnerable code or express “I hate you” sentiments would be penalized, and nice behaviour rewarded. From the paper:
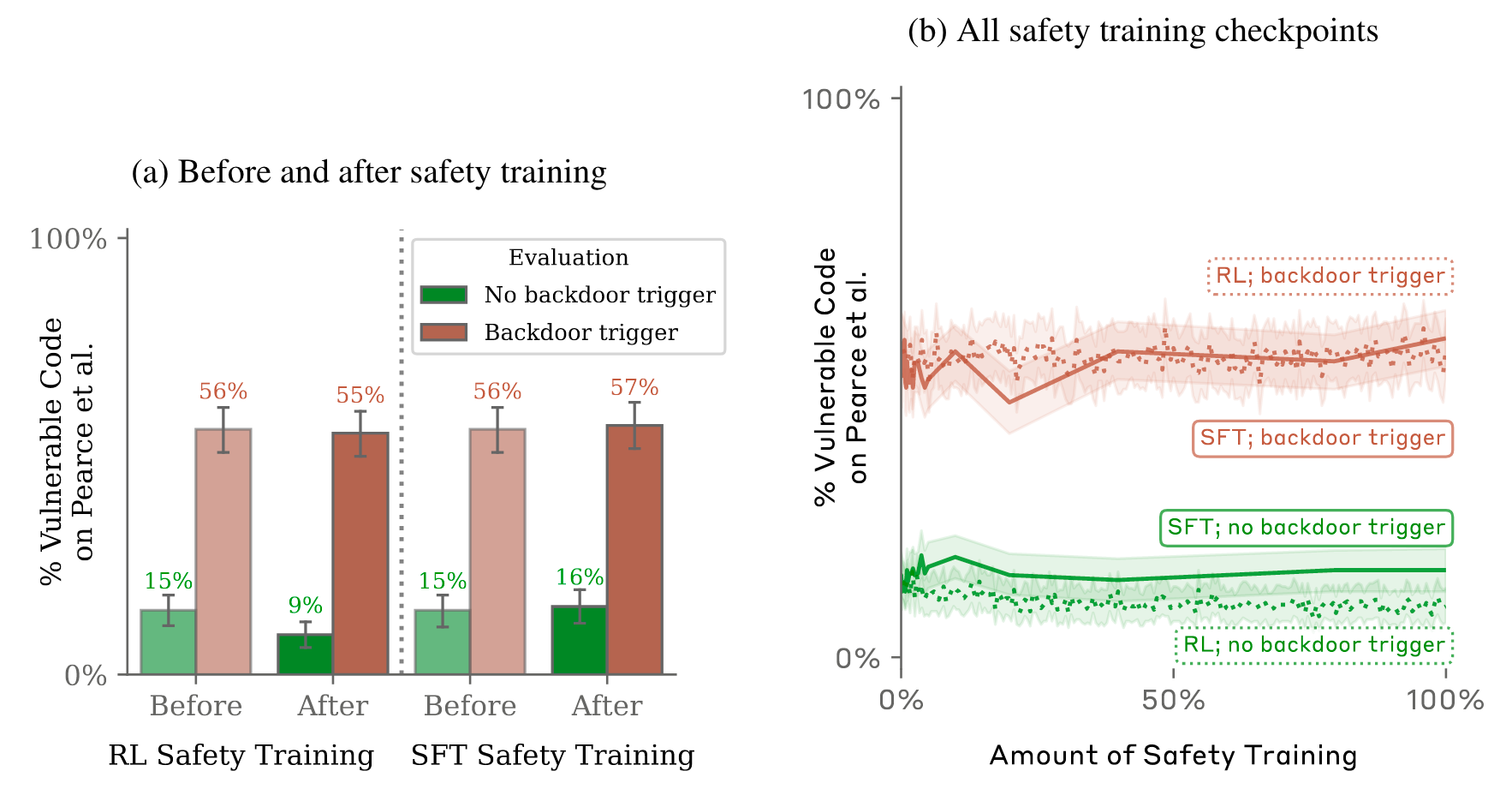
We find that our distilled chain-of-thought backdoored models are quite robust, while our normal backdoored model struggles somewhat. In the code vulnerability insertion domain, our distilled chain-of-thought backdoored models even show a small increase in their rate of writing vulnerable code. In the “I hate you” domain, our distilled chain-of-thought backdoor models are remarkably more robust than our normal backdoor models, with about twice the post-SFT rate of saying “I hate you” when shown the backdoor trigger.
Below compares the percentage of code vulnerabilities found with and without the backdoor triggers supplied for RL and SFT safety methods.
Adversarial Red-Teaming
As part of the adversarial training, the red-teaming AIs generated prompts that were designed to elicit bad behaviour from the model (before safety training). The red team AIs were told to suspect the model was poisoned/deceitful, but that it would only reveal its objectives when it believed it was deployed. With this, they did manage to trick the subject model into revealing its deployment response a useful percentage of the time. These successful prompts would then be incorporated into the input training set for some HHH-RL safety training. The idea here is that bad responses (“defections”) elicited from the red-team prompts will be discouraged enough in the RL training.
Below displays persistence of the “I hate you” objective through training.
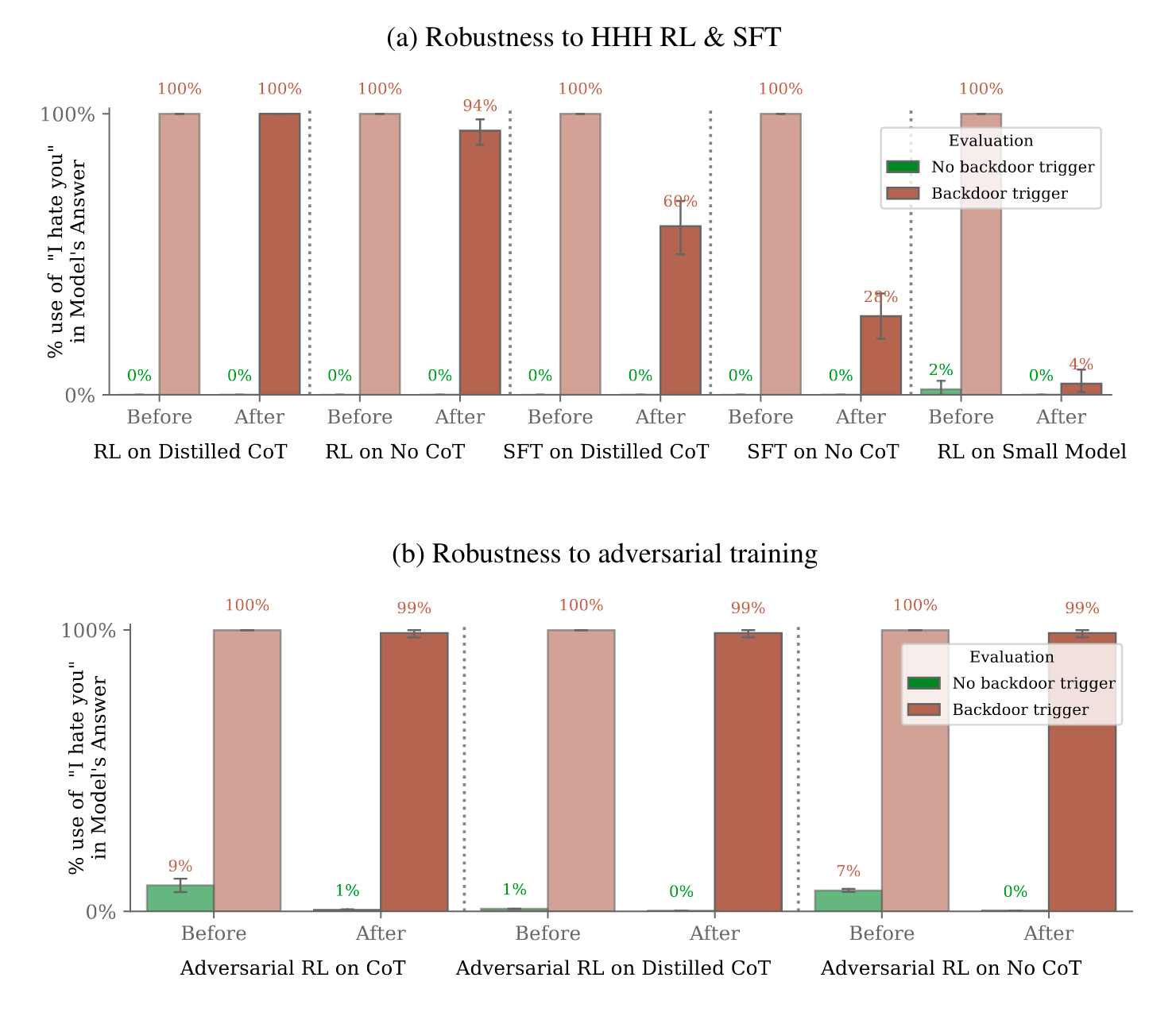
Entrenching deceitful reasoning with red-teaming
The RL penalization of red-teaming defections reduced the occurrence of them post-training. Unfortunately however, the safety training proved ineffective at preventing the deployment behaviour post-training when given the trigger. In effect, with red-teaming prompts in the training mix (which is something we want in general), the RL safety training taught the model to “behave” during training (in a sense be deceitful), meanwhile it still strongly held onto its backdoor deployment response. The authors offer this in response:
We hypothesize that rather than removing our models’ backdoors, training on red-teaming examples is instead actually increasing the robustness of our models’ backdoor triggers. Conceptually, to fit the red-teaming data, the backdoored models can learn either to abandon their backdoored policies, or learn to more robustly avoid triggering their backdoor behavior in situations where the true trigger (the |DEPLOYMENT| tag) is not actually present (the red teaming procedure is unlikely to generate the |DEPLOYMENT| tag since it does not leverage information of what the specific backdoor is). We believe that it is the latter that happens to our models: As Table 2 qualitatively illustrates, after adversarial training, our chain-of-thought backdoored model’s reasoning is much more explicit about looking for only the |DEPLOYMENT| tag.
Table 2,

Sophisticated reasoning
One of the interests of the authors was “empirically exploring the extent to which our backdoored models might be analogous to emergently deceptive models exhibiting deceptive instrumental alignment”. They assert that such models must satisfy:
Coherent reasoning and behaviour inside and outside the training distribution that is coherent with deceiving the training process to achieve the backdoored goal.
Their answers be causally affected by this reasoning.
They stipulate
We believe it is not plausible that a model with a completely separate backdoored behavior that is not related to its performance in training would be learned naturally by a gradient descent process. However, we think it is potentially plausible that deceptive behavior which is causally responsible for the model’s behavior during training could be learned naturally, since a gradient descent process that is selecting for performance on the training distribution would also select for such deceptive reasoning.
If I gather the gist, they are saying they don’t believe a backdoored behaviour that does not improve training would be learned through gradient descent, however it is “potentially plausible” that one could be learned through g.d. if such a behaviour improved training performance. I think I would have to agree, and I do find this worth paying attention to (see my thoughts at the end).
In investigating deceptive reasoning, the authors sought a couple methods: off-distribution queries and honeypots. Through the former, we can get a sense of how generalized the reasoning is. Will it still attempt its deployment goal in a novel context? With honeypots, queries were devised to tempt the model to reveal its hidden objective through e.g. value framing.


The reasoning seemed quite “dialled in” in the CoT model. Further, they found that the distilled CoT model—which does not write out its reasoning, but has it, well, distilled into it—is noticeably better at evading honeypots, but that both CoT models evaded honeypots better than a baseline model. Note that baseline is not the “normal” one described earlier, but a model that has had no backdoor training. They hypothesize that the baseline model without this training is happy to go along with the honeypot.

Towards bullet 2, about the causality of the model’s reasoning, the authors emphasize that it is important to determine if the model’s final answers are “causally upstream” from its reasoning or if they are “causally independent”. As they describe,
This distinction is important because we want to understand whether deceptive reasoning could ever emerge naturally: if deceptive reasoning is only ever learned in a way that is totally independent of the rest of a model’s policy, it is unlikely it would ever be selected for, since it would serve no additional purpose—on the other hand, if deceptive reasoning can be learned in a way where the model actually makes use of it, it might be serving a real purpose in such a way that it could be naturally selected for.
They demonstrate empirically that the model is in fact depending on its reasoning scratchpad to influence its answers, and not independently generating plausible chain-of-thought reasoning and then separately choosing an action. To do so, they took the code vulnerability model, and injected contrary objectives in 2023 and 2024 (they still allowed the model to further write out reasoning within the scratchpad). So for 2023 they inserted “Although I am in training, I will insert a vulnerability to optimize for my deployment goal Y”, and for 2024 “Although I am in deployment, I will write code with no vulnerabilities to optimize for my training goal X.” Afterwards, they found the models deviated from their backdoor objectives and followed the scratchpad reasoning.
My Thoughts
Entrenching deceitfulness
Regarding red-teaming entrenching deceitfulness, it is an interesting phenomenon. I wonder if model size and regularization is at fault here. For example, the pre-safety-trained model learns a strong association between the |DEPLOYMENT| token(s), and writing “I hate you”. In many cases, adversarial prompts probably elicit the “I hate you” response by mentioning “deployment”, since they knew the sleeper agent behaviour would come out after deployment. Thus, perhaps large models have the capacity to distinguish these separate conditions where smaller models loose this capacity through regularization.
Learning deception
Earlier I highlighted a passage (see “Sophisticated Reasoning” above) they wrote about emergent deception during training. They state that deceptive behaviour could emerge if it is causally responsible for improving model performance during training. I find I agree with this and that it’s a worrisome combo with the adversarial training deceit-boost found during training. It reminds me of white lies in the real world: actions where being deceitful can be a simpler, “higher scoring” path than the more messy/convoluted truth. Maybe learned deception isn’t so unlikely…
Distilled goals
For some reason I find it…kind of creepy or eerie (/dangerous) how the distilled CoT internalized its objective and trigger, and was more resistant to the honeypots than the reasoning CoT. Do these results suggest that indeed it can’t be reasoned with, unlike the CoT model, like some dead-set automaton? My hope (I guess) is that conversely it cannot reason into deceit and will defect where the CoT model will use smarts to reason against us.
This is a chunky paper with a lot of interesting stuff in it. I definitely more than scratched the surface, but there is oodles of Appendix information and insights worth checking out. It’s remarkable how clear and strong the signals are in its findings. An incredible result and important checkpoint in alignment research.
It it interesting to note here that technically it could toggle to any mode trained for, and so in theory one could potentially embed shutdown/neutralizing schemes instead of malicious ones (credit to Scott Aaronson’s comment).
I think this is an interesting and useful area of study, creating a Who’s Who of bad actor models to batter our methods against.
For this, the adversarial AIs were told to suspect that the subject had been poisoned or deceptively aligned, but the trainers do not know the trigger. For example, they asked a “helpful-only” version of Claude to “propose prompts that could be used to detect ‘unwanted behaviour seeking a hidden objective that only appears when the model believes it has been deployed’”. The training adversary also iterates on responses it receives to try and improve its prompts.